剖析架构模型
一、同步模型
1.1 流式处理与批量处理
“数据同步” 本质上讲属于 “数据处理”,即:从数据的一端流向另一端的数据处理,“端” 以产品为单位,包含分布式集群。那么 “数据处理” 的主要类型又可分为 “流式处理” 与 “批量处理”,二者定义、特点、起源如下,借鉴自 Flink 官网计算引擎说明:
1. 定义而言:
批量处理:对固定范围的数据集,基于 MapReduce 、 Batch 等算法,处理数据实现功能需求;
流式处理:对无固定范围数据集,基于 Event-Time 的数据结构处理算法,处理数据实现功能需求;
2. 特点而言:
“批量处理” 故名思义以批量减少调用过程中的非必要性能消耗,达到性能提升的目的,如:MapReduce。
“流式处理” 是相对于批量处理产生的,对于像日志数据、交易数据类型的,源源不断产生的数据流,基于数据自身有序性的(发生时间)数据结构,优化出来的计算方法。举个类 MapReduce 的例子,在批量处理中如果想统计 Log1、Log2 中 3:00:00 ~ 4:00:00 的 A 状态类型数据变为 B 状态类型数据的变更发生的次数,那么批量的做法是在开启对应时间窗口攒批统计再汇总加和。这时如果因为异步线程或网络传输原因导致 Log1 中一个该类型变更在批量时间窗口外(4:05:00)落盘,那么这次批量将无法计算出这个事件,只能下次批量计算解决。该例子会在 “数据同步” 类型数据处理中引发正确性问题,因此流式处理应运而生,特别适合处理 有状态的(如:时间) 无界数据流。
综上,该节试图说明数据同步适合 流式事件处理 类型,学习 TiCDC 代码过程中发现就是流式事件处理。
1.2 流处理 source 与 sink
在 TiCDC 系列分享第一篇 TiCDC系列分享-01-简述使用背景 中,提到 TiCDC 提供 At Least Once 的同步模型,At Least Once 描述的是:“在同步链路中任意组件节点发生故障时,流式处理系统的投递语义”。相关语义的全集如下:
1. At Most Once(最多一次) :算子事件仅被处理一次,即:默认下游算子均成功接收上游投递的消息,发生故障则数据丢失;
2. At Least Once(最少一次):算子事件会被处理多次,即:下游算子因故障未接收消息,上游算子发觉后会重发数据;
3. Exactly Once(有效一次) :算子时间有效处理一次,即:下游算子因故障未接收消息,对下游算子来讲会接收上游从发的数据,但对于下游算子的下游算子(例:可能是外部系统 MySQL)来讲只被有效的投递消息过一次。
在 流式处理(事件处理) 中,如: Goolge Dataflow、Flink 分别通过 “重复数据删除” 及 “分布式快照” 的方式实现 Exactly Once,Exactly Once 拥有更好的性能,但在不同的算法下也都有自己的优缺点,详情可阅读 Flink China Blog 谈谈流计算中的『Exactly Once』特性。说回 TiCDC 为什么只提供 At Least Once 不得而知,可能是综合预期、交付、排期、优化等多种因素而暂时为提供 Exactly Once 故障投递语义,相信在未来终会提供该特性。
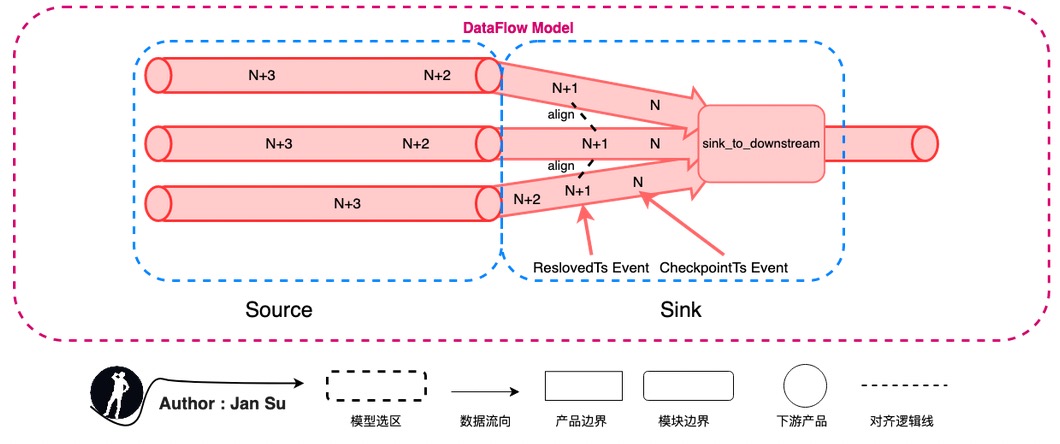
下图所示为类比通用流式引擎(Dataflow or Flink)抽象出来的同步模型,source 为发送端、sink 为接收端。目前,在 TiCDC 中有 2 部分可以归纳为该抽象类型。
1. 在 tikv cdc component 中搜集的 kv change log 投递给 TiCDC Capture 的过程;
2. 在 puller 中搜集数据投递给下游 MySQL、MQ、Others 平台的过程;
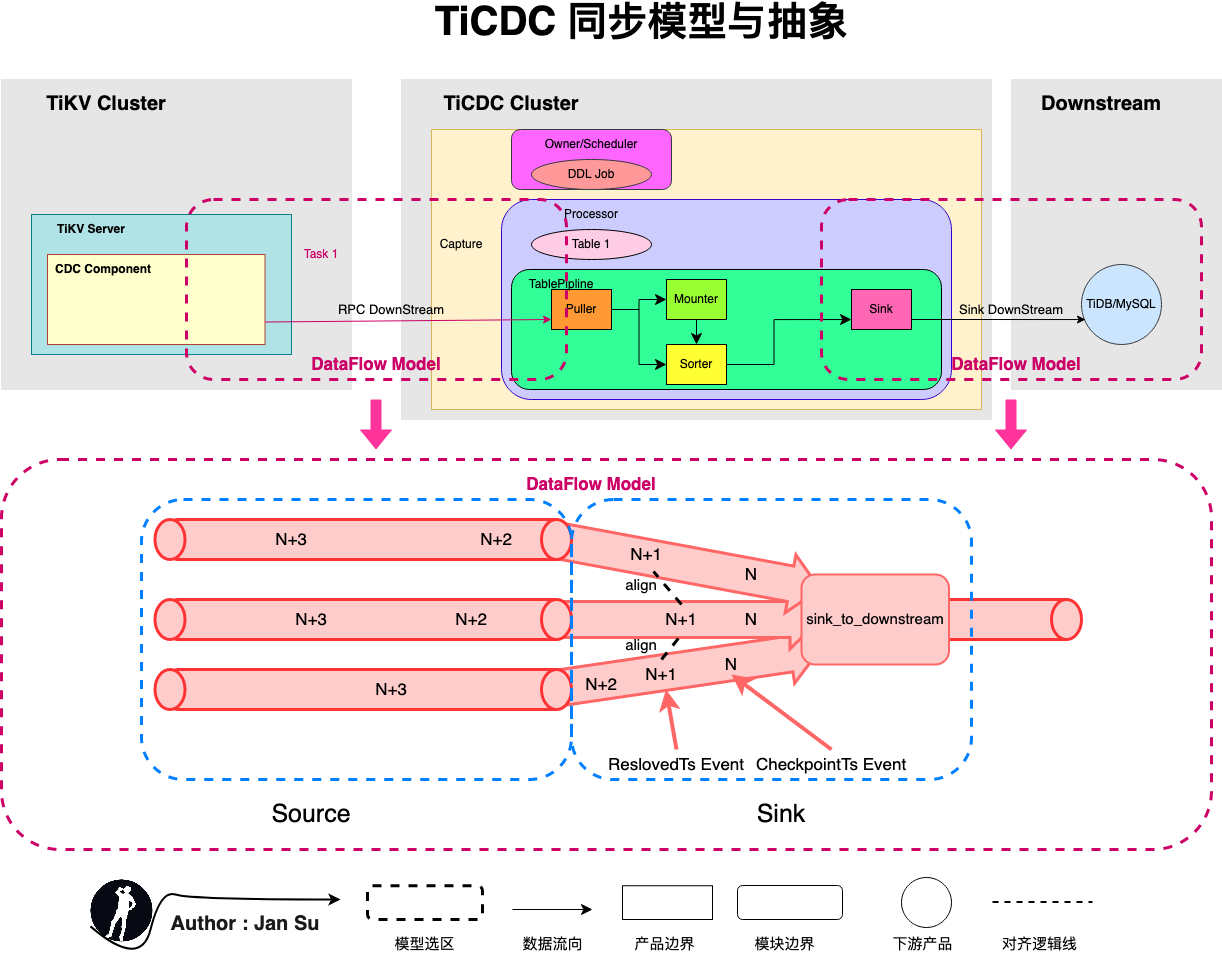
抽象为 Source、Sink 后便是可以套用到 "流式处理系统的投递语义" 中,即:在该链路中如果出现投递消息失败,则提供哪种级别的语义支持。前文已叙述 TiCDC 提供 At Least Once 语义 支持,就是会重传,重传后的重复数据重复投递,但由于 “幂等” 实现数据的一致性。
1. 如果 tikv cdc component 向 TiCDC Capture 投递消息失败,则重传;
2. 如果 TiCDC Capture 向 Downstream Platform 投递消息失败,则重传;
TiCDC 中 Source、Sink 的抽象模块对应也验证了 TiCDC 具有做 “Exactly Once” 的一些相似定义基础,只是还没有做。
二、产品架构
下图所示为 TiCDC 数据流转架构图,TiCDC 运行时是由无状态节点 Capture 组成,通过 PD 内部的 etcd 实现高可用,支持创建多个同步任务,向多个不同的下游进行数据同步。
了解 TiCDC 前需要掌握一些概念定义,如下 Owner、Processor、ChangeFeed、ReslovedTs、CheckpointTs 等等,部分概念源自 TiDB 官网解释,其余概念源自本人对相关文档的阅读与源码研究,欢迎交流。
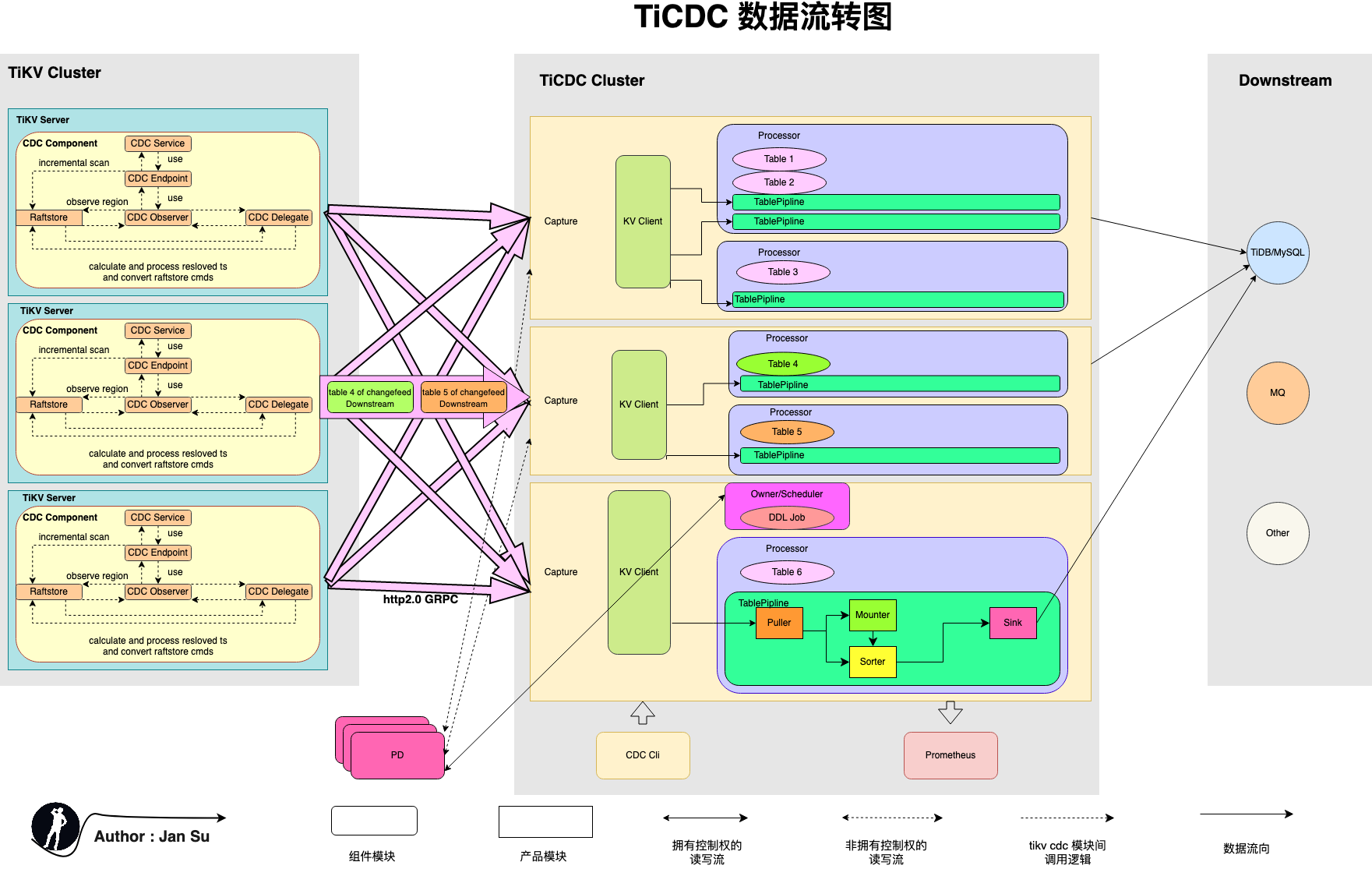
2.1 Owner
定义:一个特殊角色的 Capture。
位置:位于 Capture 内部,且会竞选自己是否可以成为 Owner,只有一个 Capture 会竞选成功成为 Owner。
作用:维护全局所有 Capture 中同步 Task 的同步状态。如:Table 转移 Capture 调度、执行 DDL、更新 changefeed 的 Global CheckpointTs 和 Global ResolvedTs。
2.2 Processor
定义:数据表的同步处理单元。
位置:位于 Capture 内部,每个 Capture 可以启动多个 Processor,Processor 的多少与 ChangeFeed 相关,即:一个多表同步 ChangeFeed 创建时被调度至各 Capture,Owner 会基于 (Capture ,ChangeFeed, Table 数量) 元组在不同 Capture 上构建 Processor。
作用:负责分配给自己的同步表的变更数据的拉取、排序、还原和分发。ChangeFeed 创建时会触发 Processor 的创建,读取被分配表的 KeyRange、Region 分布,建立 EventFeed gRPC stream。在持续推流过程中,会维护自己的 Processor ResovledTs、Processor CheckpointTs,并依据 Global ResolvedTs 向下游同步数据。
2.3 Puller
定义:从 tikv 拉取 Change log 的模块。
位置:DDL Puller 位于 Processor 内部,每个 Processor 一个。
行变更 Puller 位于 TablePipline 内部,每个 TablePipline(即:Table) 一个。
作用:持续的从 TiKV 拉取 Change Log 写到 Buffer、Sorter 中。
2.4 Mounter
定义:转译 KV Change Log 为 TiCDC Change Event 的模块。
位置:位于 Capture 内部,Mounter 对于 Capture 讲是全局线程池,但因每个 TablePipline 都会调用,算 Tablepipline 内部。
作用:解码 RawKVEntry 成 RowChangedEvent,即:转译 RawKV 成 SQL 需要的数据。
2.5 Sorter
定义:对乱序的 kv change log 进行排序的模块。 位置:位于 Tablepipline 内部,对于 unifiedSorter 封装了 Level DB,其他引擎暂不介绍,详情参考设计文档 ticdc-db-sorter。
作用:接收未排序的数据存至内部 LevelDB,并基于 CheckpointTs 排序,用于还原事务、行数据变更。
2.6 Sink
定义:向下游多协议平台同步的抽象模块。
位置:位于 Capture 内部。
作用:触发行变更事件或 DDL 变更事件,向下游同步变更数据。
2.7 ChangeFeed
定义:TiCDC 中同步任务的单位,每个 ChangeFeed 任务包含多张表的同步。
位置:位于 PD 中,ChangeFeed 创建后会被 Capture 中对应模块处理。
作用:面向用户提供易理解的 “同步任务” 语义定义。
三、ReslovedTs 与 CheckpointTs
3.1 ReslovedTs
定义:TiDB 能读取的最新一致性数据( ResolvedTs < All Unapply CommitTs ),表示 ResolvedTs 前的 tikv committed log 均被 puller 收到可还原为完整事务。
位置:位于 TiKV CDC Component 中,在数据 Apply 时观察 LockCF 变化,实现对 Region 数据变更的监控。
作用:降低 TiCDC 还原事务的延迟,即:ResolvedTS ≤ Min Region StartTS < all unapplied CommitTS。ReslovedTs 初始化、投递、推荐原理如下:
1. ResolvedTs 产生:在初始化阶段,为初始化时传入的事件戳。增量扫后,为从 RaftStore 监听的日志中获取。
2. ResolvedTs 投递:TiKV CDC Component 会向外部推送活跃 Region 的 Prewrite + Commit 的数据(携带 Ts),通过心跳推动非活跃 Region 的推进(携带 Ts)。
3. ResolvedTs 推进:ResolvedTs 又分为 Table 级、Processor 级、Global 级。Capture 从 kv client 获取的 resolved ts,按照表对所有 region 取最小的推进。即:表内排序后输出的 event 中包含 resolved ts event 存储为这个表的 resolved ts。processor 汇总自己负责的所有表的 resolved ts 和 ddl puller 的resolved ts,取最小值更新为该表的 resolved ts,owner 读取所有表的 resolved ts,取最小值更新 global resolved ts。
3.2 CheckpointTs
定义:表示 CheckpointTs 前的数据已全部同步到下游, ResolvedTs 的一种。
位置:位于 Tablepipline、Processor、Owner 中,持续推流阶段不断更新。
作用:保证事务原子性,如一事务跨域多 region,可能出现事务提交时只有部分 key 成功投递至 capture,导致无法拼出完整事务操作丢失原子性。用 checkpointTs 表示该时间点以前所有小于 checkpointTs 的 key 均已发到 Capture。
四、启动流程
总体来说,一个 ChangeFeed 的创建需要经历 “增量扫” + “持续推流” 两个阶段,详细描述如下,参考 ticdc-design:
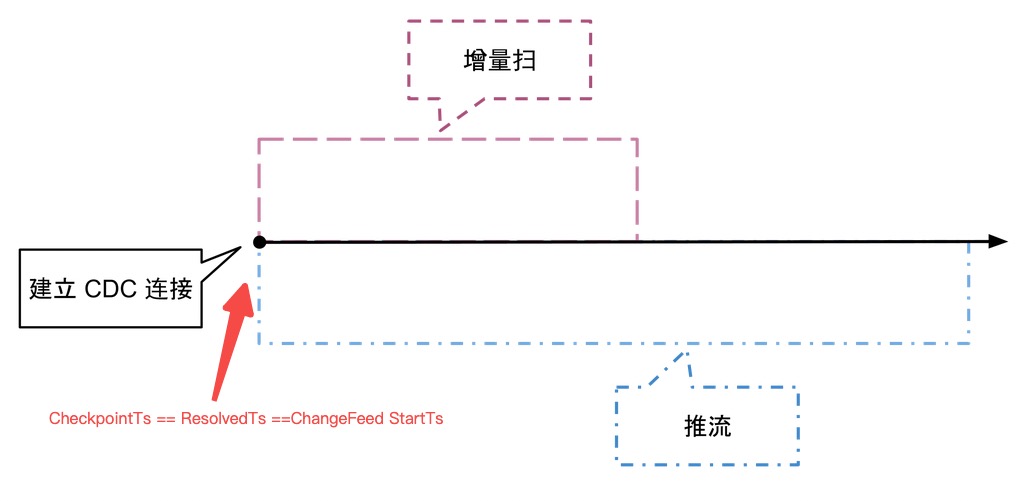
4.1 增量扫
ChangeFeed 创建请求时会带上 checkpoint_ts,TiKV 收到请求后构造一个 rocksdb snapshot ,取出 Range ( checkpoint_ts, uint64::MAX ] 大于 checkpoint_ts 所有记录。
增量扫取的是 TiKV RocksDB 中的数据, 如下例所示增量扫 (TS1,TS5] 便是,扫 LockCF + DefaultCF 并构造对应的 perwirte 记录,扫 DefaultCF 及 WriteCF 将大于 @TS1 的无锁记录,同时构建持续推流阶段。
@TS1 begin;
@TS2 update Table_Jan set name = 'Jan Su' where id = 1;
@TS3 begin;
@TS4 commit;
@TS5 update Table_Jan set name = 'Jan Su' where id = 2;
4.2 持续推流
增量扫后,TiCDC 通过 "TiKV CDC Component --> Capture --> Downstream" 持续推流阶段,实时维护 CheckpointTs、ResolvedTs。在 TiKV CDC Component 内部会维护一个 Region Map ,实时监听 RaftStore 的日志变更实现向 Capture 的推流。在 Capture 内部会在排序收到的分散的 TiKV Change Log ,并还原事务并向下游分发消费数据。
4.3 监听日志
增量扫后,TiKV CDC Component 会在 Coprocessor 中注册一个 Observer 监听 RaftStore 产生的 TiKV Change Log,持续提供增扫后持续推流需要的数据。
五、状态维护
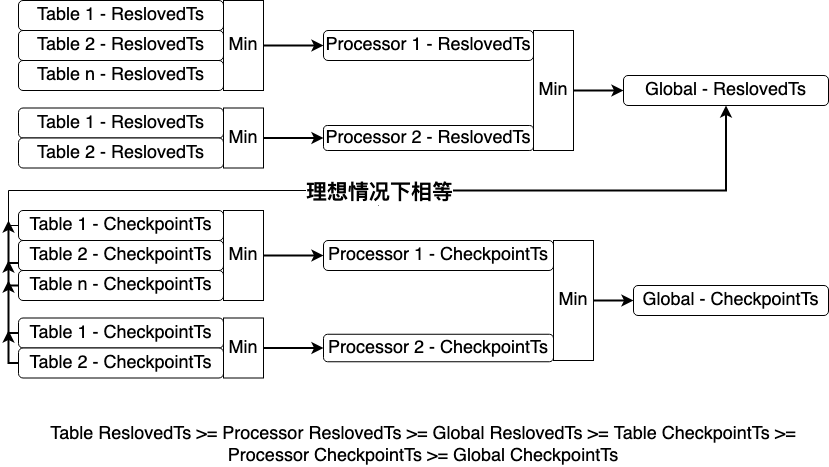
对于 DML 变更,所有 Processor 同步至 Global ResolvedTs ,写到下游后更新 CheckpointTs。对于 DDL 变更,所有 processor CheckpointTs 同步至等于 DDL commitTs 再向下游执行 DDL。Global ResolvedTs、Processor ResolvedTs 计算方式如下,并且维护下面一张图表:
1. Global ResolvedTs 由 owner 计算,取值为所有 Processor 的 ResolvedTs 和 DDL puller 的 ResolvedTs 的最小值;
2. Processor ResolvedTs 由 Processor 计算,取值为所有 Tablepipline 的 ResolvedTs 最小值;
六、状态容错
所谓状态容错,即:数据投递端发生故障时,TiCDC 如何提供 “At Least Once” 的容错保证。
下面举 2 个可能发生状态容错的场景,其实 Table 的 CheckpointTs、ResolvedTs 可以类似的理解为 “Exactly Once” 中的 Snapshot 机制,但是提供的是 “At Least Once” 语义保证。
1. 以 tikv cdc component 为数据投递端为例: 那么接收端便是 TiCDC Capture,假设 Tablepipline 负责的 table 的 change log 数据(N+2)已经存在于 Puller 中,但此时由于 Region Leader 变更导致 GRPC 和 TiKV 之间建立的 DownStream 连接需要重新建立,那么会基于 Table ResolvedTs (N+1)重新拉数据,但是该数据已经存在 Puller 中造成了数据冗余。“At Least Once” 语义保证后拉取的数据也会还原成冗余的数据变更,即同步到下游时后面的数据会覆盖前面的数据,操作幂等。
2. 以 TiCDC Capture 为数据投递端为例: 那么接收端便是 Downstream Platform,当 Table 所在的 Capture 挂掉时会被 Owner 检测到并在其他 Capture 上创建新的 Processor、Tablepipline,并基于 PD 中存储的 CheckpointTs 重新向 TiKV CDC Component 请求构建 GRPC Stream 连接拉取 TiKV Change Log 数据,实现节点高可用容错处理。
七、引用参考
1. Apache Flink 概念介绍:有状态流式处理引擎的基石
2. Flink Exactly Once 状态容错论文解析 Lamport 的 “Distributed Snapshots”
3. Flink Exactly Once 状态容错原文 Distributed Snapshots: Determining Global States of Distributed Systems
4. Flink 官网计算引擎说明
5. TiCDC系列分享-01-简述使用背景
6. Exactly Once 之 “分布式快照” 与 “重复数据删除” 实现方式的比较
7. TiCDC 设计文档之 ticdc-db-sorter
8. TiCDC 设计文档之 “增量扫 + 推流” 介绍