一、论文摘要
- 适用场景: LSM-tree 是一种基于磁盘的 Data Structure,旨在为一段时间内持续插入、删除的文件提供低成本索引,从而解决传统 B-tree 在持续写出场景下,维护活心事务 I/O 成本翻倍的问题。在插入比检索更常见的场景中,Lsm-tree 更为有用。如,对于历史表和日志文件。
- 维护方式: Lsm-tree 使用算法延迟和批量索引更改,以类归并排序的方式将 update 信息内存传递到磁盘。
- 性能对比: 与传统的b树访问方法相比,该算法可从内存或磁盘连续读取范围数据,大大减少了磁盘臂的移动,但由于算法本身读放大,索引查询可能会丧失一定 I/O 效率。
二、论文简介
商业不断应用条件下,传统事务日志关注崩溃回复,但通常提供日志检索需求不断增加。通过扩充物理内存方式不是长久之计,如果在历史记录表上提供索引查询支持将极具价值。LSM-Tree 通过算法实现了索引 node 顺序与 key 顺序 无关的,高频插入时的查询效率优化。 Lsm-tree 论文简介部分使用 “5 分钟原则”、“TPC-A benchmark 实验” 分别引出论文的论证标准、和论证方式。本人撰写本文的目的为帮助读者更好理解 Lsm-tree 原文
- The 5 Minute Rule for Trading Memory for Disc Accesses and the 5 Byte Rule for Trading Memory for CPU Time 论文发表于 1986 年,文中给出了一套公式测算使用磁盘代价与内存代价测算公式。
- “TPC-A benchmark 实验” 是著名的基准测试实验,含有大量历史记录查询场景。
三、基本思想
3.1 Lsm-tree 两重要组件
Lsm-tree 由 Disk tree 和 Memory tree 两部分组成,历史数据存放在 Disk tree 中。当数据进入 Lsm-tree 的时先写序列化日志以用于崩溃恢复,随后数据进入内存 C0 层。每次检索数据都需先查 C0 层、再查 C1 层,读放大延时因此产生。
数据在 C0 层时无 IO 消耗,但受经济因素(内存比磁盘贵)限制,当 C0 层数据达到容量限制会有进程将数据刷到磁盘。与 B-tree 比较, Lsm-tree 在顺序磁盘方向有所优化,根节点下各层子节点均已连续磁盘数据页的形式存储,提高磁盘臂使用效率。每层有多节点和有单节点的区别的原因是,多子节点用于有利于大范围数据扫描,单子节点用于最小化缓存。
块大致分两类:
- emptying block: 被合并前,不断减少数据的块,称为掏空块;
- filling block: 当空块大小增长到阈值,被重写到 C1 层新块,不断增加数据的块,称为填充块;
滚动落盘包含一系列步骤,每次从 C1 层多块(磁盘页)读读取多个叶子结点到内存,将 C0 层数据在内存中与 C1 层数据合并,从而减少 C0 层空间占用。当 “filling block” 被写满后,会被重写到新的磁盘空闲区。新合并的节点在父节点的右侧。当新节点容量增长到阈值时,会继续向下滚动上述合并过程。
旧 block 数据被合并到新 block 后不会立即被重写,而是保留用于崩溃恢复。同时,被更新叶子结点的父节点也会缓存在内存中一段时间,以为最小化 I/O 及更新子节点位置信息,直至旧 block 无效时才会被删除。
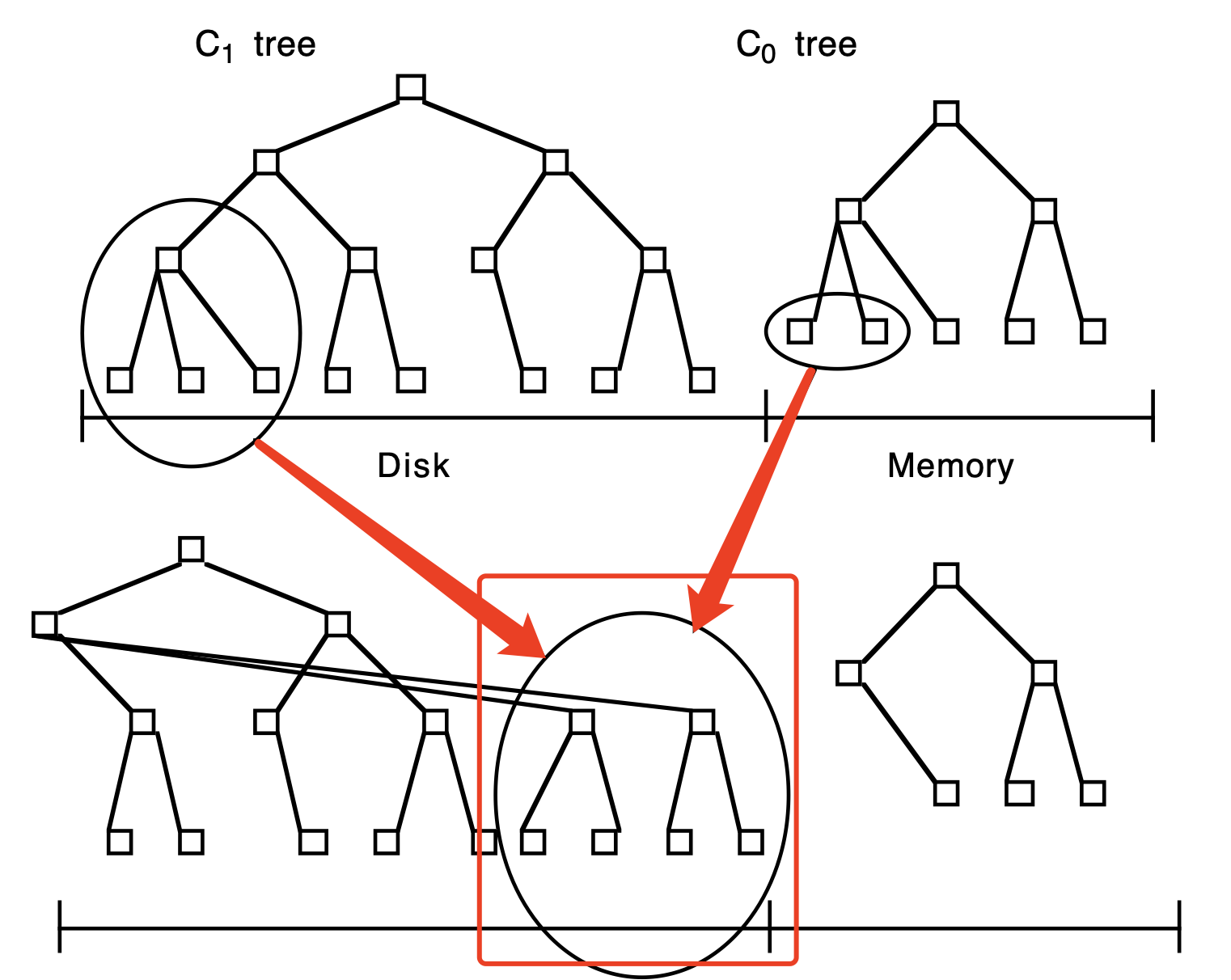
3.1.1 组件增长细节
Lsm-tree 增长初期会先将记录插入内存中的 C0 组件中,因为不需要考虑落盘后,检索数据损失 CPU 效率,所以 C0 节点的容量可以是任意的。当 C0 数据容量增长到阈值时,以 batch 方式重构到 C1 后,删除掉 C0 中数据。随从左到右放置在 C1 的页块不断增加,当 C1 组件数据增长达到阈值后,被写入到磁盘。
C1 层节点信息更新到磁盘的情况
- 某个包含多磁盘页的块被写满;
- 跟节点分裂增加了 C1 树深度;
- 执行 chekckpoint 时;
3.2 Lsm-tree 性能与多组件
3.3 Lsm-tree 并发与崩溃恢复
3.4 磁盘访问算法比较
四、文章结论
五、引用文章
Paper -- The 5 Minute Rule for Trading Memory for Disc Accesses and the 5 Byte Rule for Trading Memory for CPU Time
Paper -- The Log-Structured Merge-Tree (LSM-Tree)
CSDN Blog -- The 5 minute rule: 一部paper的连续剧 by historyasamirror