TiDB-TiSpark依靠TiUP工具协助部署集群
时间:2021-01-16
TiSpark原理讲解
- TiSpark是构建在 Spark Catalyst 引擎之上的,使用 TiSpark 之前需要安装并运行 Spark 集群;
- TiSpark 实现了如 TiDB 一样的多种计算下推到 TiKV 层面计算,减少 Spark 需要处理数据加速查询;
- TiSpark 可以利用 TiDB 的内建的统计信息选择更优的查询计划;
- TiSpark 直接操作 TiKV,相比使用 Spark 结合 JDBC 的方式写入,不仅可以实现事务而且写入速度会更快;
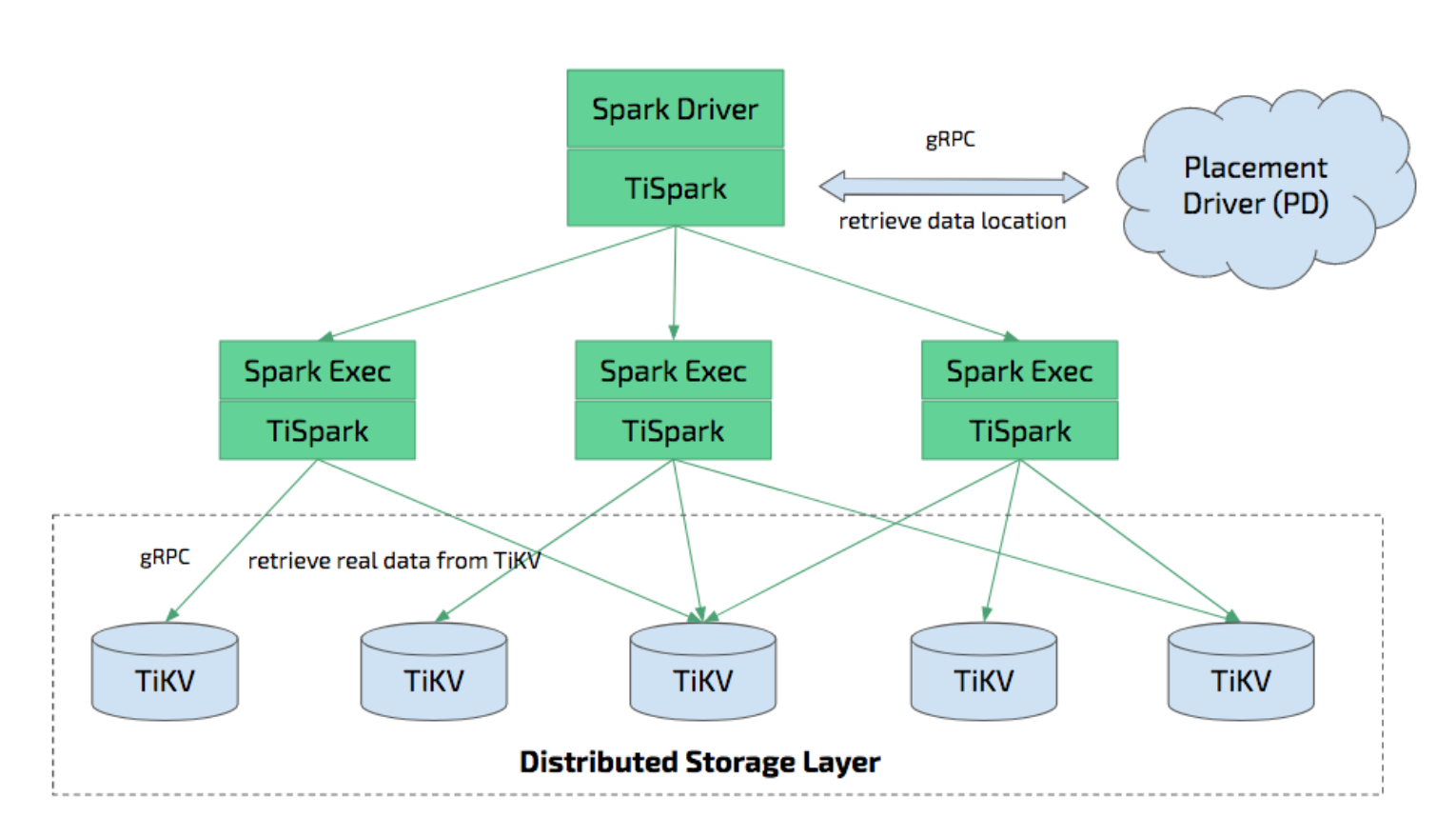
TiSpark与Spark下载
shell
# tiup 安装 spark
[tidb@tiup-tidb41 conf]$ tiup install spark
# tiup 安装 tispark
[tidb@tiup-tidb41 conf]$ tiup install tispark
# 查看安装结果
[tidb@tiup-tidb41 conf]$ tiup list --installed
Available components:
Name Owner Description
---- ----- -----------
spark pingcap Spark is a fast and general cluster computing
tispark pingcap tispark
......
......
# 进入到 tiup 隐藏目录下,查找相关镜像文件
[tidb@tiup-tidb41 spark-2.4.3-bin-hadoop2.7]$ cd ~/.tiup/components/
[tidb@tiup-tidb41 components]$ ll |grep spark
drwxr-xr-x 3 tidb tidb 20 Jan 16 05:40 spark
drwxr-xr-x 3 tidb tidb 21 Jan 11 07:51 tispark
# 复制 Spark 到目录 TiDB 部署目录下,统一部署路径,方便以后运维
[tidb@tiup-tidb41 components]$ cd spark/v2.4.3/
[tidb@tiup-tidb41 v2.4.3]$ ll
drwxr-xr-x 13 tidb tidb 211 Jan 16 05:40 spark-2.4.3-bin-hadoop2.7
[tidb@tiup-tidb41 v2.4.3]$ cp -rp spark-2.4.3-bin-hadoop2.7 /data/tidb-deploy/
Spark环境部署与检验
- 在正式使用 TiSpark 之前需要先部署 Spark 集群,因为 TiSpark 仅是是一个 Jar 包,实现了 Spark 的扩展
- 本例仅使用一个 Spark Master 和一个 Spark Slave 来完成演示(Stand alone),大家可以一句自己需求搭建完整的 Spark 集群
shell
# 进入部署路径 conf 路径下
[tidb@tiup-tidb41 conf]$ cd /data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/conf/
[tidb@tiup-tidb41 conf]$ cp spark-defaults.conf.template spark-defaults.conf
# 编写 spark-defaults 配置文件,加入 PD 集群信息、TiSpark 扩展
[tidb@tiup-tidb41 conf]$ vi spark-defaults.conf
[tidb@tiup-tidb41 conf]$ cat spark-defaults.conf
spark.tispark.pd.addresses 192.168.169.41:2379,192.168.169.42:2379,192.168.169.43:2379
spark.sql.extensions org.apache.spark.sql.TiExtensions
[tidb@tiup-tidb41 conf]$ cp spark-env.sh.template spark-env.sh
# 编写 Spark-env 扩展文件
[tidb@tiup-tidb41 conf]$ vi spark-env.sh
[tidb@tiup-tidb41 conf]$ cat spark-env.sh
export SPARK_MASTER_IP=192.168.169.41
export SPARK_LOCAL_IP=192.168.169.41
export SPARK_EXECUTOR_MEMORY=1G # SPARK EXECUTOR 所能使用的内存
export SPARK_EXECUTOR_cores=2 # SPARK EXECUTOR 所能使用的核心数
export SPARK_WORKER_CORES=2 # SPARK WORKER 所能使用的核心数
- 启动 Spark Master 和 Spark Slave
shell
# 启动 Spark Master
[tidb@tiup-tidb41 sbin]$ cd /data/tidb/deploy/spark/sbin
[tidb@tiup-tidb41 sbin]$ sh start-master.sh
# 启动 Spark Slave(在tikv上操作)
[tidb@tiup-tidb41 sbin]$ cd /data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/sbin
[tidb@tiup-tidb41 sbin]$ ./start-slave.sh spark://192.168.169.41:7077
# 检查 Spark Master 和 Slave 是否均已启动
[tidb@tiup-tidb41 conf]$ ps -ef|grep spark
tidb 10091 1 0 06:10 pts/0 00:00:27 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.275.b01-0.el7_9.x86_64/jre/bin/java -cp /data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/conf/:/data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host tiup-tidb41 --port 7077 --webui-port 8080
tidb 10155 1 0 06:12 pts/0 00:00:21 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.275.b01-0.el7_9.x86_64/jre/bin/java -cp /data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/conf/:/data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://192.168.169.41:7077
tidb 11487 8542 0 08:25 pts/0 00:00:00 grep --color=auto spark
至此,tidb+spark集群就搭建完成
拓展TiSpark与spark-shell验证
shell
# 进入 spark 命令行客户端,并执行 spark.sql("show databases").show 查看 TiDB 中所有数据库
scala> [tidb@tiup-tidb41 conf]$ spark-shell
21/01/16 07:13:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/01/16 07:14:11 INFO TiSparkInfo$: Supported Spark Version: 2.3 2.4
Current Spark Version: 2.4.3
Current Spark Major Version: 2.4
Spark context Web UI available at http://tiup-tidb41:4040
Spark context available as 'sc' (master = local[*], app id = local-1610799251405).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_275)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("show databases").show
21/01/16 07:14:34 INFO ReflectionUtil$: tispark class url: file:/data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/jars/tispark-assembly-2.3.11.jar
21/01/16 07:14:34 INFO ReflectionUtil$: spark wrapper class url: jar:file:/data/tidb-deploy/spark-2.4.3-bin-hadoop2.7/jars/tispark-assembly-2.3.11.jar!/resources/spark-wrapper-spark-2_4/
21/01/16 07:14:50 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
21/01/16 07:14:50 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
+------------+
|databaseName|
+------------+
| default|
| dumptest2|
| user_east|
| jan|
+------------+