使用背景
一、项目背景
如 PingCAP 官网 所述,TiCDC 的使用场景主要有 “数据库灾备” 及 “数据集成”。熟悉 TiDB 周边生态的爱好者一定知道 “TiDB Binlog” 这一与 TiCDC 功能相似的工具,那么为什么要重复工作呢?
答案是 “TiDB Binlog” 无法存在以下(非全部)种种问题,对于 “TiDB Binlog” 还不熟悉的伙伴参考 TiDB Binlog 简介:
1. “TiDB Binlog” 扩展性差,如:Drainer 存在 “单点” 及 “性能” 问题,拆分 Drainer 无法保证 “数据行变更有序性”;
2. “TiDB Binlog” 性能低下,如:“TiDB Binlog” 仅支持单 kafka 单 partition 写入,无法提高 kafka 吞吐量;
3. “TiDB Binlog” 通用型差,如:写成 binlog 写成文件需要使用 Reparo 解析 SQL 语句,不支持 Maxwell、Canal 等通用协议;
4. “TiDB Binlog” 同步痛点,如:binlog 写到下游受 GRPC max message 限制多,如 Pump 的 gRPC message 超过限值 等等;
5. “TiDB Binlog” 可用性差,如:单点的 Drainer 一旦出现问题同步将中断,不存在一定程度的自愈功能;
由此 TiCDC 应运而生,通过直接捕获 TiKV Change Log ,将表作为拆分单元调度至各 Capture 中,并发向下游同步数据解决扩展性问题。可 kafka 多 partition 写入,并支持 Maxwell、Canal 等多种通用协议,解决同步性能、生态通用性问题。当同步超时、 Capture 同步表数量不均、Capture 挂掉等情况时,TiCDC 存在调度机制及 At Least Once 保证数据完整性前提下,调度实现自愈合。
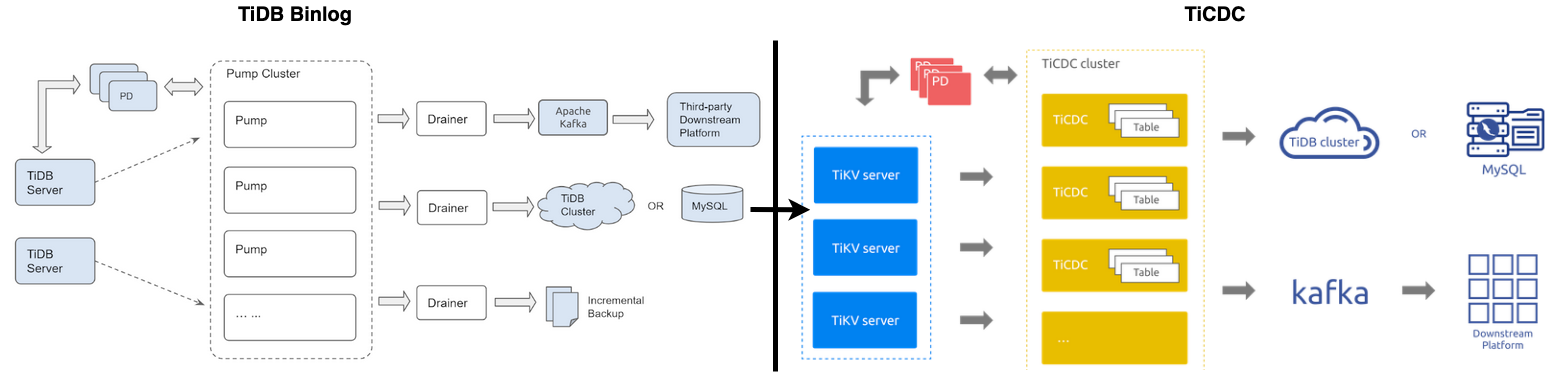
二、工具位置
首先,熟知 TiCDC 使用方法,必先明确其在 TiDB 生态工具所处的位置及作用。
1. 作用而言:数据库如果是个只进不出的 “貔貅”,那么必将被市场所抛弃,也就是所谓的 “数据孤岛”,TiCDC 兼顾同步性能、数据完整性,一致性、生态通用性,实现了数据从 "流入-> TiDB ->流出" 的闭环。此外,谈性能如果抛弃了场景(不深入讨论),那就是在耍流氓,没有任何一个款产品能完胜所有场景,TiDB 同样也有自己的舒适区、痛点区。有了 TiCDC 之后,用户可以轻松实现数据的流转,把 TiDB 用在使用场景的舒适区。
2. 位置而言:TiCDC 介于 TiDB 与下游目的端之间,下游包含兼用 MySQL 通许协议的所有产品、平台(如:TiDB、MySQL、RDS、三方云平台等)。用户还可基于通用消息队列输出协议自定义开发,现 TiCDC 支持的协议有:Open Protocol 、Canal-JSON 、 Canal 、Avro 、 Maxwell 等协议,有些协议仅部分支持,详情参考 --> TiCDC 支持的协议指南
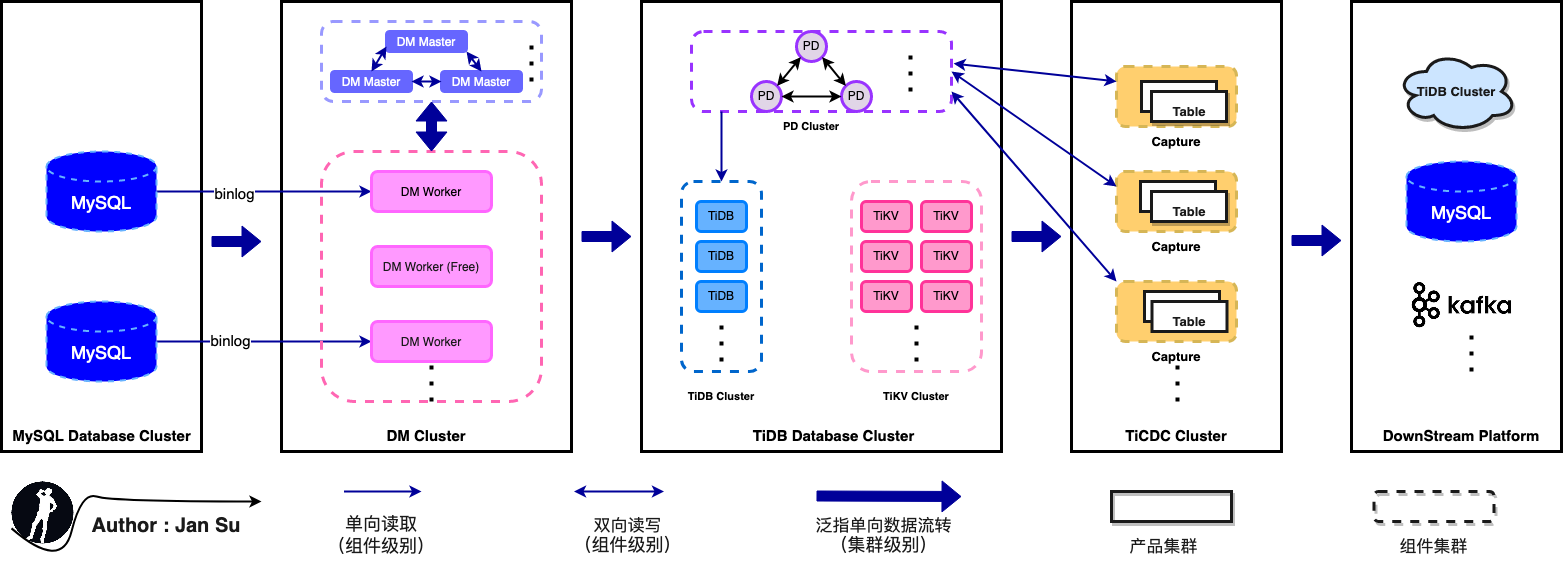
其次,TiCDC 几乎囊括所有主流 “数据同步” 的使用场景,下图便是 “MySQL --> TiDB --> Others” 的经典组合拳。至于其他协议的数据库(Oracle、PG)如何流入 TiDB,等同于如何流入 MySQL,因为 TiDB 兼容 MySQL 通讯协议,一定存在较成熟的解决方案。
三、使用情况
注意:下述公司均通过 AskTUG 搜索相关文章得到,即:分享文章中有提及该公司正在使用 TICDC。下述公司仅是通过搜索手段可得知的公司,还有许多商业客户要求不对外透露、或还未来得及透露。
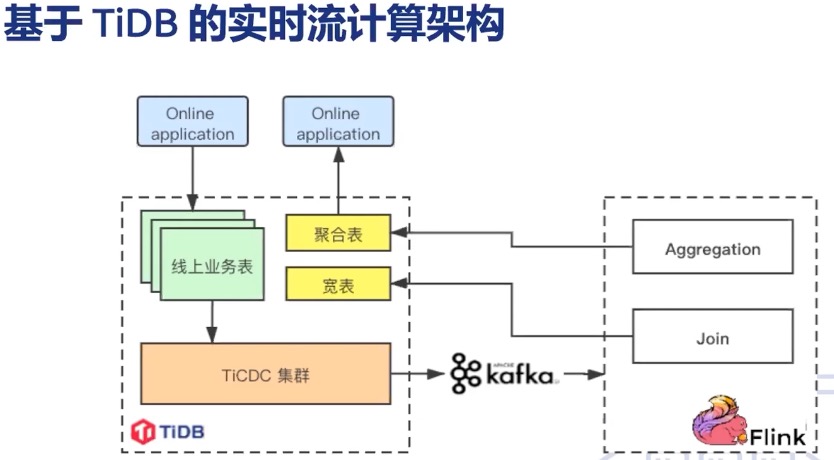
3.1 小红书
从 张亿皓老师 在 【PingCAP Infra Meetup】No.131 TiCDC 的生态和社区建设 中分享可知,小红书基于 TiCDC 在业务中进行内容审核、笔记标签推荐、增长审计。实现如下图,基于 "TiDB --> TiCDC --> Kafka --> Flink --> TiDB" 这样一条链路实现与架构中其他数据源的聚合计算。
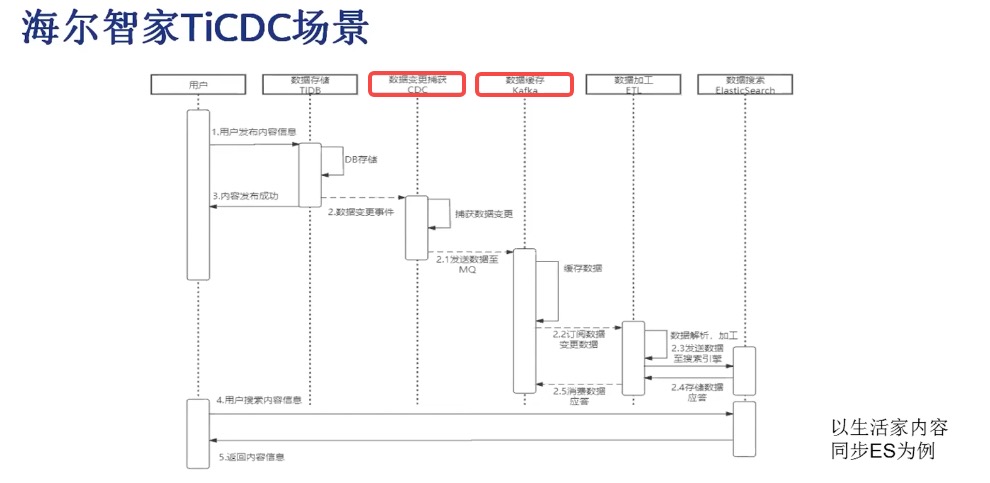
3.2 海尔智家
从 姚翔老师 在 【PingCAP Infra Meetup】No.131 TiCDC 的生态和社区建设 中分享可知,海尔智家基于 TICDC 在业务中进行搜索、推荐。将用户数据、生活家信息数据基于 "TiDB --> TiCDC --> Kafka --> ES" 这样一条链路实现 Kafka 日消费量在 300 万左右的近实时搜索功能。从描述中可知截止 2019-09-19 分享时,TiCDC 在不涉及表数量、LOB 字段、网络延时等细节情况下,同步能力边界为:正常同步在 “毫秒” 级,抖动情况下在 “秒级”(10s 以内)。
此外,从 Github -- Question and Bug Reports 中可以看出 TiCDC 存在 mqSink flushes data synchronously,casing low performance、Poor incremental scan performance where they are frequent insertions、improve performance of syncer 等多个提升同步性能的 RoadMap,对于 TiCDC 的同步性能是一个持续优化的过程。
3.3 360
从 代晓磊老师 在 BLOG - TiCDC 应用场景解析 中分享可知,360 基于 TiCDC 实现并参与立项 增量数据抽取、同城双集群热备、流处理求 的需求。
四、使用方法
4.1 部署 TiCDC
下述测试环境搭建 TiCDC ,目的测试、学习 TiCDC 同步功能。172.16.6.155:8300 及 172.16.6.196:8300 的 CDC 组件会在扩容后出现。
[tidb@Linux-Hostname ~]$ tiup cluster display tidb-test
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
172.16.6.155:9093 alertmanager 172.16.6.155 9093/9094 linux/x86_64 Up /home/data/tidb-home/data/alertmanager-9093 /home/data/tidb-deploy/alertmanager-9093
172.16.6.155:8300 cdc 172.16.6.155 8300 linux/x86_64 Up /data/deploy/install/data/cdc-8300 /home/data/tidb-deploy/cdc-8300
172.16.6.196:8300 cdc 172.16.6.196 8300 linux/x86_64 Up /data/deploy/install/data/cdc-8300 /home/data/tidb-deploy/cdc-8300
172.16.6.155:3000 grafana 172.16.6.155 3000 linux/x86_64 Up - /home/data/tidb-deploy/grafana-3000
172.16.6.155:2379 pd 172.16.6.155 2379/2380 linux/x86_64 Up|UI /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.194:2379 pd 172.16.6.194 2379/2380 linux/x86_64 Up /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.196:2379 pd 172.16.6.196 2379/2380 linux/x86_64 Up|L /home/data/tidb-home/data/pd-2379 /home/data/tidb-deploy/pd-2379
172.16.6.155:9090 prometheus 172.16.6.155 9090/12020 linux/x86_64 Up /home/data/tidb-home/data/prometheus-9090 /home/data/tidb-deploy/prometheus-9090
172.16.6.155:4000 tidb 172.16.6.155 4000/10080 linux/x86_64 Up - /home/data/tidb-deploy/tidb-4000
172.16.6.196:4000 tidb 172.16.6.196 4000/10080 linux/x86_64 Up - /home/data/tidb-deploy/tidb-4000
172.16.6.155:20160 tikv 172.16.6.155 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160
172.16.6.194:20160 tikv 172.16.6.194 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160
172.16.6.196:20160 tikv 172.16.6.196 20160/20180 linux/x86_64 Up /home/data/tidb-home/data/tikv-20160 /home/data/tidb-deploy/tikv-20160
TiCDC 在 4.0.6 版本 GA,建议使用 4.0.6 及以后的版本,详情参考 --> TiCDC 官方文档,扩容步骤如下。
[tidb@Linux-Hostname ~]$ cat scale-out-cdc.yaml
cdc_servers:
- host: 172.16.6.155
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
- host: 172.16.6.196
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
[tidb@Linux-Hostname ~]$ tiup cluster scale-out tidb-test scale-out-cdc.yaml
4.2 同步至 Kafka
由于本人之前没接触过 kafka ,本着熟悉 TiCDC 也要了解其周边工具的目的,从 kafka 官网 进行了简单入门,如有任何正确性问题可及时评论区交流。
简单了解后,个人觉得 kafka 类似 GoLang 中的 Channel,区别在于提供了高性能的、分布式的、高可用的、弹性的、容错的、安全的 “事件流平台” 服务。 kafka 官网介绍其事件流式处理机制如下图所示,Topic 作为分发消费的逻辑单元,Partition 作为最小存储单元,以 Hash Key 或其他策略将 Event 划分到多个 Partition 中,提供高吞吐性能。
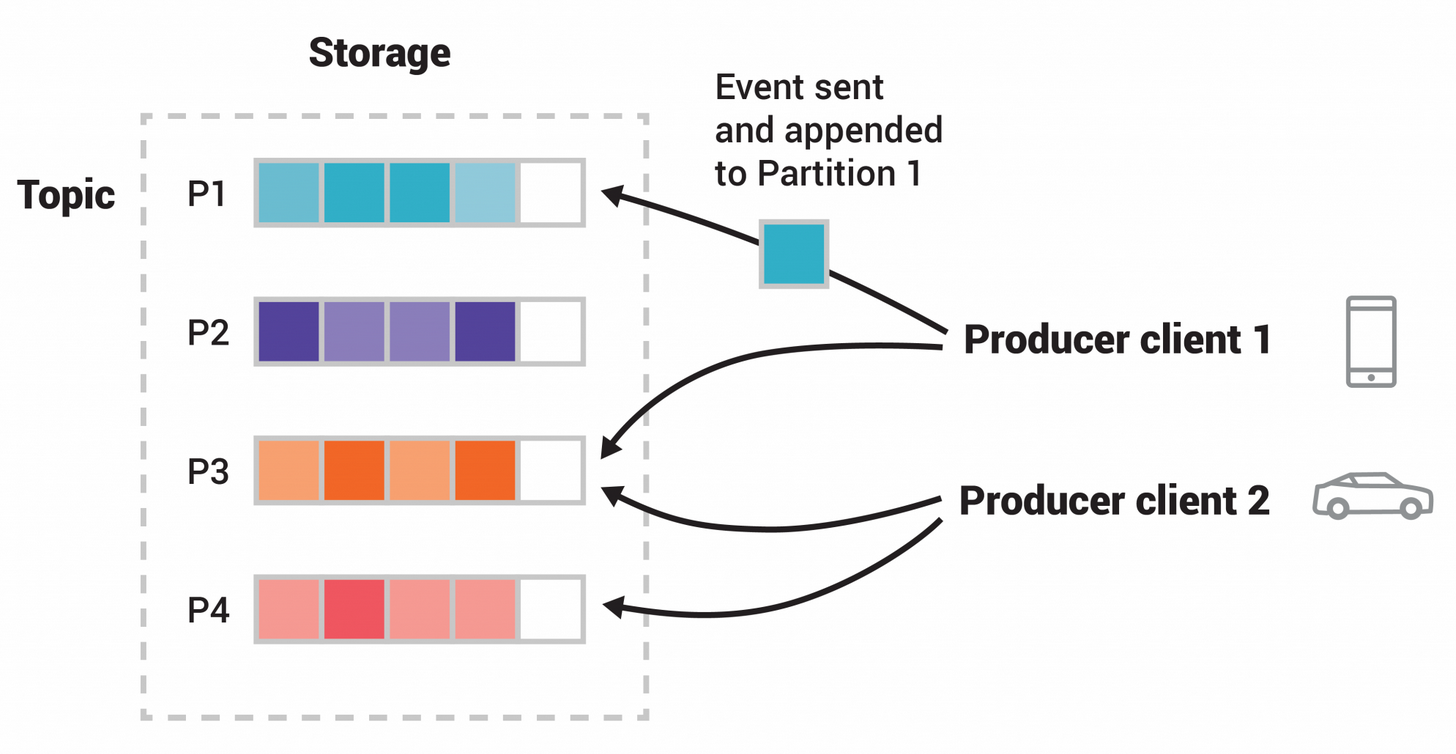
下面简单试用下 kafka,操作步骤如下,目的为从 kafka 中解析出 TiCDC 分发给 kafka 的消息,不深入研究 kafka 体系及调优。
# 安装 Java 运行环境
[tidb@kafka1 ~]$ yum install java-1.8.0-openjdk.x86_64
[tidb@kafka1 ~]$ java -version
openjdk version "1.8.0_322"
# 依据 kafka quickstart 在 172.16.6.155、172.16.6.196 两个 server 架起 kafka
[tidb@kafka1 ~]$ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1g/kafka/3.1.0/kafka_2.13-3.1.0.tgz --no-check-certificate
[tidb@kafka1 ~]$ tar -xzf kafka_2.13-3.1.0.tgz
[tidb@kafka1 ~]$ cd kafka_2.13-3.1.0
[tidb@kafka1 ~]$ bin/zookeeper-server-start.sh config/zookeeper.properties
[tidb@kafka1 ~]$ bin/kafka-server-start.sh config/server.properties
# 创建 partition 为 2、topic-name 为 tidb-test 的 topic
[tidb@kafka1 ~]$ bin/kafka-topics.sh --create --topic tidb-test \
--bootstrap-server 172.16.6.155:9092,172.16.6.196:9092 \
--partitions 2
Created topic quickstart-events.
# 查看 topic-name 为 tidb-test 的 topic 的配置情况,可以看到 partition 为 2
[tidb@kafka1 ~]$ bin/kafka-topics.sh --describe --topic tidb-test \
--bootstrap-server 172.16.6.155:9092,172.16.6.196:9092
Topic: tidb-test TopicId: OjM6FFrBQtqyEB4sVWmYCQ PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tidb-test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tidb-test Partition: 1 Leader: 0 Replicas: 0 Isr: 0
# 创建 TiCDC 到 kafka 的 changefeed 同步,并复用手动创建的 tidb-test topic
[tidb@kafka1 ~]$ tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="kafka://172.16.6.155:9092/tidb-test?protocol=canal-json&kafka-version=2.4.0&partition-num=2&max-message-bytes=67108864&replication-factor=1"
tiup is checking updates for component cdc ...
Starting component `cdc`: /home/tidb/.tiup/components/cdc/v6.0.0/cdc /home/tidb/.tiup/components/cdc/v6.0.0/cdc cli changefeed create --pd=http://172.16.6.155:2379 --sink-uri=kafka://172.16.6.155:9092/tidb-test?protocol=canal-json&kafka-version=2.4.0&partition-num=2&max-message-bytes=67108864&replication-factor=1
[2022/05/12 16:37:09.667 +08:00] [WARN] [kafka.go:416] ["topic's `max.message.bytes` less than the `max-message-bytes`,use topic's `max.message.bytes` to initialize the Kafka producer"] [max.message.bytes=1048588] [max-message-bytes=67108864]
[2022/05/12 16:37:09.667 +08:00] [WARN] [kafka.go:425] ["topic already exist, TiCDC will not create the topic"] [topic=tidb-test] [detail="{\"NumPartitions\":2,\"ReplicationFactor\":1,\"ReplicaAssignment\":{\"0\":[0],\"1\":[0]},\"ConfigEntries\":{\"segment.bytes\":\"1073741824\"}}"]
Create changefeed successfully!
......
# 利用 sysbench 向 jan.sbtest1 中插入 2 行数据
[tidb@kafka1 ~]$ sysbench oltp_read_write --mysql-host=127.0.0.1 \
--mysql-port=4000 \
--mysql-db=jan \
--mysql-user=root \
--mysql-password= \
--table_size=2 \
--tables=1 prepare
# 从 kafka 中解析 TiDB 的数据变更如下
[tidb@kafka1 ~]$ bin/kafka-console-consumer.sh --topic tidb-test \
--from-beginning --bootstrap-server 172.16.6.155:9092,172.16.6.196:9092
{"id":0,"database":"jan","table":"sbtest1","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1652344970654,"ts":1652344977538,"sql":"","sqlType":{"c":1,"id":4,"k":4,"pad":1},"mysqlType":{"c":"char","id":"int","k":"int","pad":"char"},"data":[{"c":"83868641912-28773972837-60736120486-75162659906-27563526494-20381887404-41576422241-93426793964-56405065102-33518432330","id":"1","k":"1","pad":"67847967377-48000963322-62604785301-91415491898-96926520291"}],"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1652344970654,"ts":1652344977538,"sql":"","sqlType":{"c":1,"id":4,"k":4,"pad":1},"mysqlType":{"c":"char","id":"int","k":"int","pad":"char"},"data":[{"c":"38014276128-25250245652-62722561801-27818678124-24890218270-18312424692-92565570600-36243745486-21199862476-38576014630","id":"2","k":"2","pad":"23183251411-36241541236-31706421314-92007079971-60663066966"}],"old":null}
{"id":0,"database":"jan","table":"","pkNames":null,"isDdl":true,"type":"QUERY","es":1652344966953,"ts":1652344969305,"sql":"CREATE DATABASE `jan`","sqlType":null,"mysqlType":null,"data":null,"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":null,"isDdl":true,"type":"CREATE","es":1652344970604,"ts":1652344975305,"sql":"CREATE TABLE `sbtest1` (`id` INT NOT NULL AUTO_INCREMENT,`k` INT DEFAULT _UTF8MB4'0' NOT NULL,`c` CHAR(120) DEFAULT _UTF8MB4'' NOT NULL,`pad` CHAR(60) DEFAULT _UTF8MB4'' NOT NULL,PRIMARY KEY(`id`)) ENGINE = innodb","sqlType":null,"mysqlType":null,"data":null,"old":null}
{"id":0,"database":"jan","table":"sbtest1","pkNames":null,"isDdl":true,"type":"CINDEX","es":1652344973455,"ts":1652344978504,"sql":"CREATE INDEX `k_1` ON `sbtest1` (`k`)","sqlType":null,"mysqlType":null,"data":null,"old":null}
# 实验结束清理 172.16.6.155、172.16.6.196 两个 server 架起 kafka 环境
# 首先 ctrl + c 关闭所有终端启动的前台进程
[tidb@kafka1 ~]$ rm -rf /tmp/kafka-logs /tmp/zookeeper
4.3 同步至 MySQL
在 172.16.6.155:3306 本地装个 MySQL,指定相关参数后便可创建订阅任务,id 为 simple-replication-task,在 Grafana 监控面板中可观察到同步进度。MySQL 对于 DBA 讲一定是较为熟悉的工具,因此验证同步等步骤便不赘述。
[tidb@Linux-Hostname ~]$ tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="mysql://jan:123123@172.16.6.155:3306/?time-zone=&worker-count=16&max-txn-row=5000" \
--changefeed-id="simple-replication-task" \
--sort-engine="unified" \
--config=changefeed.toml
tiup is checking updates for component cdc ...
Starting component `cdc`: /home/tidb/.tiup/components/cdc/v6.0.0/cdc /home/tidb/.tiup/components/cdc/v6.0.0/cdc cli changefeed create --pd=http://172.16.6.155:2379 --sink-uri=mysql://jan:123123@172.16.6.155:3306/?time-zone=&worker-count=16&max-txn-row=5000 --changefeed-id=simple-replication-task --sort-engine=unified --config=changefeed.toml
[2022/04/12 16:58:40.954 +08:00] [WARN] [mysql_params.go:143] ["max-txn-row too large"] [original=5000] [override=2048]
Create changefeed successfully!
......
五、引用文章
1. 【PingCAP Infra Meetup】No.131 Why and how we build TiCDC
2. 【PingCAP Infra Meetup】No.131 TiCDC 的生态和社区建设3. 官方文档 -- TiCDC
4. 官方文档 -- TiDB Binlog
5. 官方 FAQ -- Pump 的 gRPC message 超过限值
6. Github Design Doc -- TiCDC 支持的消息队列输出协议指南
7. Github Question and Bug Reports -- TiCDC 提升性能规划路径
8. AskTUG Blog -- 代晓磊 TiCDC 应用场景解析9. 官方文档 -- Kafka
此外,AskTUG 作为 TiDB 官方支持生态社区,建议大家来这里 https://tidb.net/blog/70588c4c 一起讨论。